はじめに
しばらく品切れが続いていました M5Stack Core2 を買うことができました。嬉しいです。 😀

Core2 には PSRAM が 8M ついているということで、そのあたりを確認しつつ、ハローワールドがてらメガドライブエミュレーター(Genesis Plus GX)を移植してブートさせてみました。
ソースコードを github で公開しています。
Genesis-Plus-GX M5Stack Core2 porting (no optimize and super slow)

まだビルドしてエミュレーターの起動を確認したところまでのソース断面となっていますので、最適化はまったくしておらずとっても遅いです。
後述しますが、単純に不足したメモリーを SRAM から拡張のクロックが 80MHz PSRAM にメモリーを逃したのと、LCD への仮想 VRAM 転送で何も工夫をしていないためです。
(速くする方法を思いついたらちょこちょこいじるかもしれません。また、いい方法があったらぜひお教えください!)
この記事では M5Stack Core2 上でこういった少し大きめのソースをビルドするノウハウと、PSRAM の使い方を紹介してみたいと思います。
esp-idf のビルドシステムを使った M5Stack Core2 アプリのビルド
M5Stack Core2 の標準の C/C++ 開発キットは Arduino IDE となっていますが、移植元となっている Genesis-Plus-GX のソースツリーが比較的大きいのと、各コンパイルオプションなども細かく修正しながら作業したかったので、esp-idf ビルドシステムを使って M5Stack Core2 向けのバイナリーの作成を行っています。
esp-idf が提供する Makefile を用いるとプロジェクトの構成を次のようにすることができます。なお、esp-idf の 4系のバージョンでは cmake を使うように変わっていますが、ここでは esp-idf 3.3 系を使うため Makefile 方式としています。
+ components
+ arduino (https://github.com/espressif/arduino-esp32)
+ m5stack
+ M5Core2 (https://github.com/m5stack/M5Core2)
component.mk
+ genplus
[ソース]
component.mk
+ esp-idf (https://github.com/espressif/esp-idf)
+ main
main.cpp
component.mk
sdkconfig
Makefile
main と components ディレクトリの構造と各コンポーネントしたに配置された components.mk とルートの sdkconfig と Makefile が esp-idf のビルドシステムが認識する要素です。
そのまま使いたい時は、m5stack-genplus を git clone --recursive していらないファイル消すのが簡単かもです。:D
プロジェクトテンプレートリポジトリーと How to create のドキュメントをつくりました。また、github actions で自動ビルドもかけれるようにしています。使う場合は github にログインして以下から Use This Template ボタンを押して、自身のリポジトリーを作成してプログラミングを開始すると便利です。
https://github.com/h1romas4/m5stack-core2-template
esp-idf build system template for M5Stack Core2.
さて、M5Core2 ライブラリーが依存するプロジェクトは esp-idf と arduino-esp2 ですが、現在 Arduino IDE で提供されている一式がどの断面を使っているのかが分からなかったので、ビルドが通るものを試行錯誤して、以下のバージョンでソースツリーに git submodule で固定して導入しています。
現在リリース版の arduino-esp32 は v1.0.4 の esp-idf 3.2 依存ですが、これではビルドが通らず未リリースの arduino-esp32 v1.0.5 相当で、esp-idf は 3.3 の最終コミットを使っています。 (どうも esp-idf v3.2 系及び v3.3.5 タグだと必要なファイルがなかったり、コンパイルエラーになるなどビルドが通りませんでした)
(2021/6)現在の最新版の組み合わせは次のようになっています。
| name | version | hash |
| esp-idf | 3.3.5 | |
| arduino-esp32 | 1.0.6 | |
| M5Core2 | 0.0.3(latest) | |
(2022/10 追記) esp-idf 4系 / Arduino 2 系に依存を変更したプロジェクトを以下に作成していますので参考にしてみてください。
https://github.com/h1romas4/m5stack-core2-wasm3-as
M5Stack Core2 With Wasm3/AssemblyScript Demo
git submodule で導入しておくと、バージョンが切り替わったときの上げ下げやヒストリーの確認も容易かと思います。(このようにしておくとプロジェクトごとに依存のバージョンを固定できます)
ビルドは、各 OS に対応した xtensa-esp32 のツールチェイン(gcc)を導入後、make するだけで M5Stack Core2 向けのバイナリーが作成できます。 m5stack-genplus の github をビルドする手順は次のようになります。 (Windows では MSYS2 の窓より…)
# submodule があるので --recursive 指定
git clone --recursive https://github.com/h1romas4/m5stack-genplus.git
cd m5stack-genplus
# This repository includes eps-idf
export IDF_PATH=$(pwd)/esp-idf
# CPU 4コア CPU の場合 -j4 とコアすると速い
make -j4
# 書き込み & 実行
make flash monitor
sdkconfig ファイル
sdkconfig ファイルは esp-idf や esp-idf に対応した各コンポーネントが使う define の定義です。これは make menuconfig コマンドでメニューから生成することができます。
m5stack-genplus リポジトリーには sdkconfig がコミットされていますので各種設定済みで、変えるのは転送先のシリアルポートの設定くらいですが、esp-idf や arduino-esp32 のどの機能を使うかなどなどの設定ができます。
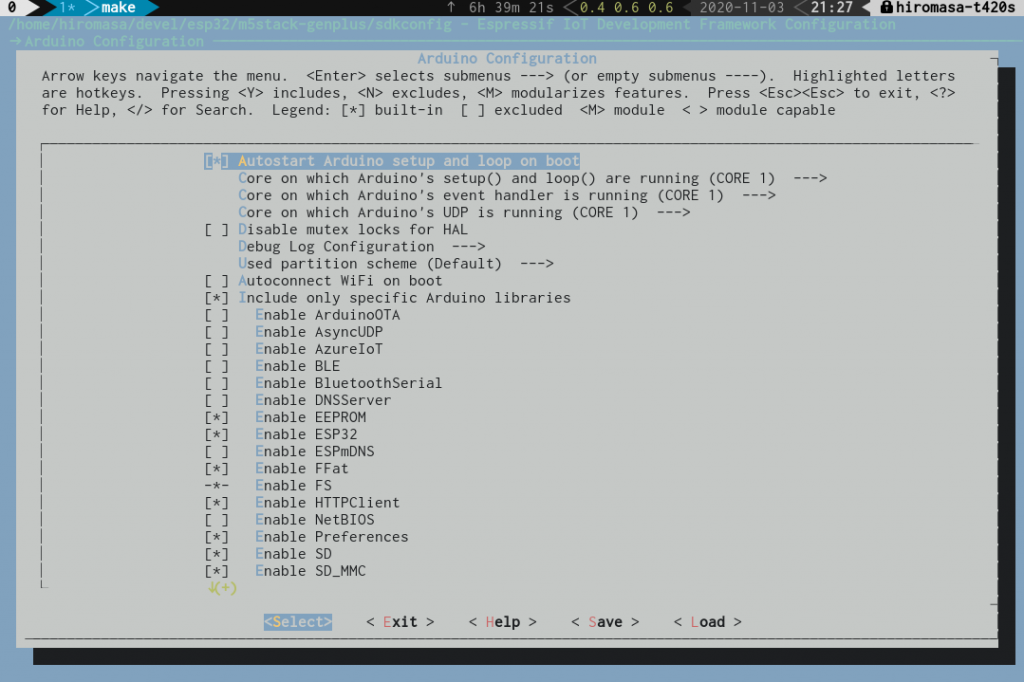
保存すると sdkconfig に値が書き込まれますが、基本的に make や C/C++ 中の define 定義集のようなものなので、キー名でソースコードを grep すると何が有効になったのかが分かります。
component.mk ファイル
各 component.mk の中にはそのコンポーネントで使われるソースファイルやインクルードファイルの位置、CFLAGS などのコンパイルオプションが定義できます。
Genesis Plus GX モジュールでは次のように定義しています。
COMPONENT_SRCDIRS := core core/z80 core/m68k core/input_hw core/sound core/cart_hw core/cart_hw/svp core/ntsc m5stack
COMPONENT_ADD_INCLUDEDIRS := core m5stack core/cart_hw core/cart_hw/svp core/cd_hw core/debug core/input_hw core/m68k core/ntsc core/sound core/themor core/z80
CFLAGS := \
-DLSB_FIRST \
-DUSE_16BPP_RENDERING \
-DMAXROMSIZE=131072 \
-DHAVE_ALLOCA_H \
-DALT_RENDERER \
-DALIGN_LONG \
-DM5STACK \
-fomit-frame-pointer \
-Wno-strict-aliasing \
-mlongcalls
利用できるオプション値は次のドキュメントから参照できます。
Optional Project Variables
ライブラリーなどを M5Stack に移植して動作させる時は、CFLAGS や CPPFLAGS などが容易に設定できますので便利に使えるのではないかと思います。components ディレクトリに任意の名前でディレクトリを作成してソースをがばっと入れ、component.mk を書いてあげればビルド対象になります。
またライブラリーにユーザー設定がある場合は Kconfig.projbuild をつくって配置することで、make menuconfig(sdkconfig) 用のメニュー定義も入れることができるようです。
PSRAM の使い方 (.bss セグメントを逃がす)
esp-idf で大きめのプログラムをリンクすると、
region `dram0_0_seg' overflowed by 1995968 bytes
このようなエラーメッセージでリンクできない場合があります。これは static の領域を確保する .bss セグメントが足りない場合に出力されます。Genesis Plus GX のビルドでは当初、上記のように 2MB 近く足りませんでした。
この .bss セグメントを PSRAM にもっていくオプションがあり、次の menuconfig の設定から有効にすることができます。
https://docs.espressif.com/projects/esp-idf/en/v3.3.4/api-guides/external-ram.html
→ Component config → ESP32-specific → SPI RAM config
→ Allow .bss segment placed in external memory
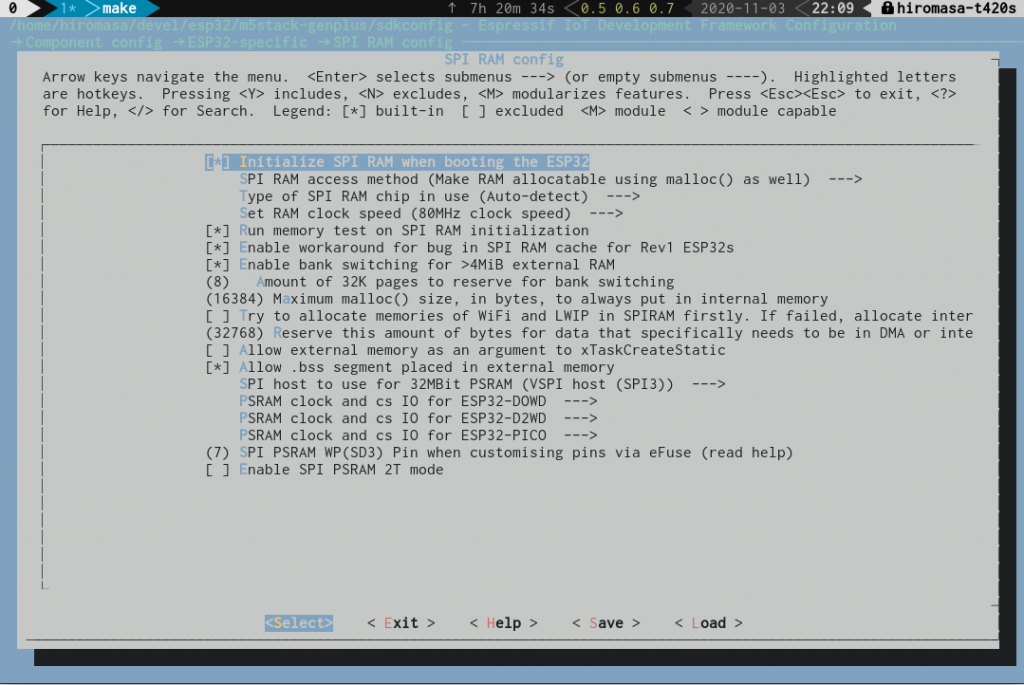
define 値的には CONFIG_SPIRAM_ALLOW_BSS_SEG_EXTERNAL_MEMORY となりますので esp-idf を grep してみると分かりやすいです。このオプションを有効にした後、ソースファイル上の static 変数に EXT_RAM_ATTR をつけると、PSRAM に領域を持っていくことができます。
#ifdef M5STACK
#include "esp_attr.h"
#endif
#ifdef M5STACK
EXT_RAM_ATTR static uint32 bp_lut[0x10000];
#else
static uint32 bp_lut[0x10000];
#endif
イメージ的にはこんな感じになります。 EXT_RAM_ATTR は未定義はブランクなので、これでも大丈夫です。
#ifdef M5STACK
EXT_RAM_ATTR
#endif
static uint32 bp_lut[0x10000];
なお、PSRAM は CPU から最大 80MHz の SPI で接続されており、通常の SRAM より速度が遅く、転送レートは最大で SRAM 960MB/sec に対して 40MB/sec ほどのようです。このため、主要なロジックで使われるメモリーを載せると処理速度が低下してしまうはずです。
How slow is PSRAM vs SRAM (anyone have quantitative info?)
Internal SRAM is 32bit @ 240MHz max, so 960MByte/second. PSRAM is 4-bit @ 80MHz, so 40MByte/second.
PSRAM の使い方 (malloc)
PSRAM がコンフィグレーションで有効になっていると、通常の malloc 関数で PSRAM も使ってくれます。
https://docs.espressif.com/projects/esp-idf/en/v3.3.4/api-guides/external-ram.html
Support for external RAM
PSRAM ではなく速い SRAM 側に確定で確保したいなど、明示的にどちらから取得するかを決めたい場合は、次の設定ができます。
→ Component config → ESP32-specific → SPI RAM config
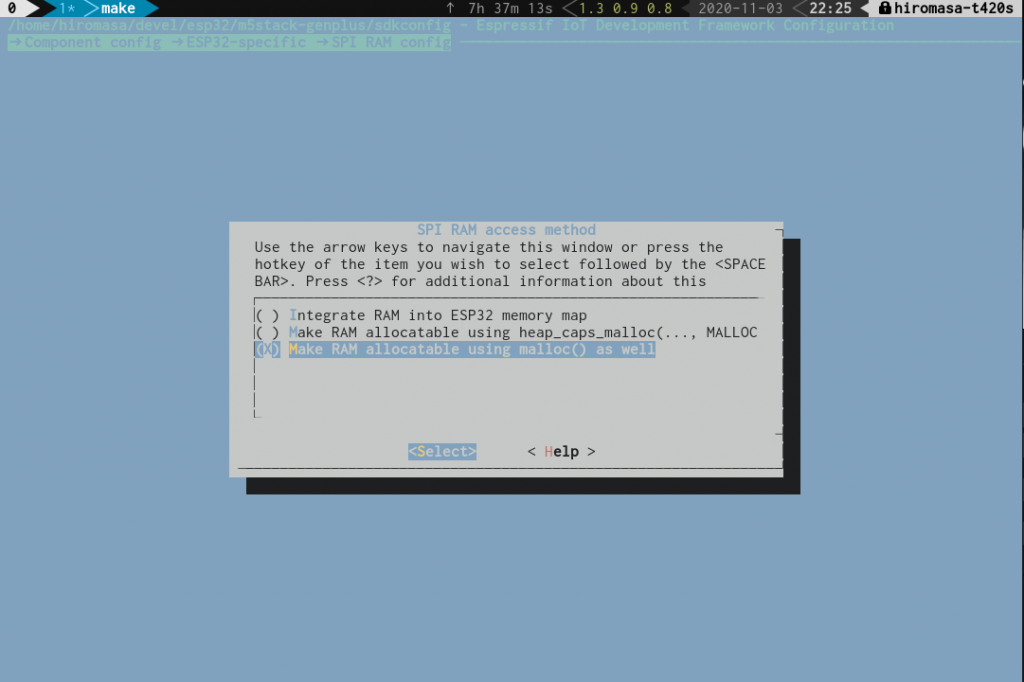
また、M5Stack Core2 には 8MB の PSRAM が搭載されていますが、使えるのは 4MB までのようで、それより上の 4MB を使う場合は himem API で別途取得するようです。(今回は未検証)
https://docs.espressif.com/projects/esp-idf/en/v3.3.4/api-reference/system/himem.html
The himem allocation API
VS Code の設定(おまけ)
あんまり関係ありませんが、開発は VS Code + C/C++ Extention で行いました。インテリセンスの効きもよく大変良いです。
VS Code ではプロジェクトに .vscode/c_cpp_properties.json を配置して次のように設定すると便利です。
{
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/build/include",
"${workspaceFolder}/components/arduino/cores/**",
"${workspaceFolder}/components/arduino/libraries/**",
"${workspaceFolder}/components/arduino/variants/esp32",
"${workspaceFolder}/components/m5stack/M5Core2/**",
"${workspaceFolder}/esp-idf/components/**"
],
"defines": [
"ESP32=1",
"ARDUINO_ARCH_ESP32=1",
"BOARD_HAS_PSRAM",
"ARDUINO=10800",
"M5STACK",
"LSB_FIRST",
"USE_16BPP_RENDERING",
"MAXROMSIZE=131072",
"HAVE_ALLOCA_H",
"ALT_RENDERER",
"ALIGN_LONG"
],
"intelliSenseMode": "gcc-x64",
"compilerPath": "~/devel/toolchain/xtensa-esp32-elf/bin/xtensa-esp32-elf-gcc",
"cStandard": "c11",
"cppStandard": "c++17"
}
],
"version": 4
}
defines にはコンパイルオプションで指定した define を定義しておくといい感じにパーサーが感知して色分けしてくれます。sdkconfig の define 値については、自動的に生成された build/include/sdkconfig.h を読むことで自動的に反映するようになっています。
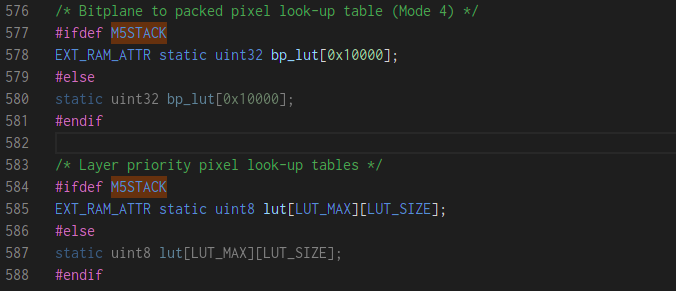
例えばですが、上記のようにコンパイルオプションで定義された M5STACK 値の ifdef が有効になって else がグレーアウトしますので分かりやすいです。
おわりに
というわけで、M5Stack Core2 ハローハッピーワールドでした。
他にもいくつかプログラムを動かしてみましたが、タッチセンサーもよく動いて M5Stack Core2 楽しいです。ビルドも固まりましたので、引き続き何かつくってみたいです!