ワンショットではあるものの大きめのデータを処理する場合、データベースに入れたらいいなぁとおもいつつも、データベースサーバ起動するのが面倒だったり create table するのが面倒だったりすることがよくあります。
そんな時は組み込み可能な DB ってことで、こんなことに使ったら怒られそうではありますが OrientDB と Groovy の組み合わせ。タイムリーにも Twitter の自分の全ツイートが取得可能となったということで抽出をかけてみました。 🙂
OrientDB Graph-Document NoSQL dbms
OrientDB is an Open Source NoSQL DBMS with both the features of Document and Graph DBMSs. It’s written in Java and it’s amazing fast: can store up to 150,000 records per second on common hardware.
#もちろん OrientDB はサーバモードもありますです。
Twitter の全ツイートダウンロードですが、「ユーザ情報」の下の方にあるリクエストボタンをクリックするとメールリンクで CSV が送られてくるようです。
とりあえず Eclipse にファイルやライブラリを配置して・・・。(./file/Tweets は OrientDB によってつくられた DB の物理ファイルです)
まずは CSV2OrientDB のローダをかきました。 TweetsLoader.groovy
import au.com.bytecode.opencsv.CSVReader
import com.orientechnologies.orient.core.db.document.ODatabaseDocumentTx
import com.orientechnologies.orient.core.record.impl.ODocument
// define CSV header (exclude expanded_urls)
def header = [
"tweet_id"
,"in_reply_to_status_id"
,"in_reply_to_user_id"
,"retweeted_status_id"
,"retweeted_status_user_id"
,"timestamp"
,"source"
,"text"]
// load CSV
CSVReader reader = new CSVReader(new FileReader("./file/tweets.csv"))
List myEntries = reader.readAll()
reader.close()
// create OrientDB
ODatabaseDocumentTx db =
new ODatabaseDocumentTx("local:./file/Tweets").create()
// import CSV
myEntries.each {
ODocument doc = new ODocument("Tweet");
def index = 0
header.each { name ->
doc.field(name, it[index])
index++
}
doc.save()
}
// close OrientDB
db.close();
これを実行すると .csv が “local:./file/Tweets” DB に読み込まれます。スキーマレスなので適当にロードできます。お手軽。 🙂
でもって、できたデータベースにクエリーを発行します。 Groovy が入っているつぶやきを単純に like にて。 TweetsQuery.groogy
import com.orientechnologies.orient.core.db.document.ODatabaseDocumentTx
import com.orientechnologies.orient.core.record.impl.ODocument
import com.orientechnologies.orient.core.sql.query.OSQLSynchQuery
// open OrientDB
ODatabaseDocumentTx db =
new ODatabaseDocumentTx(
"local:./file/Tweets").open("admin", "admin");
// query
List<ODocument> result = db.query(
new OSQLSynchQuery<ODocument>(
"select * from Tweet where text like '%Groovy%'"));
// output
result.each {
println it.field("text")
}
// close OrientDB
db.close();
手抜きコード申し訳ない(笑)
という感じで実行結果です。 あとは煮るなり焼くなりできますね。
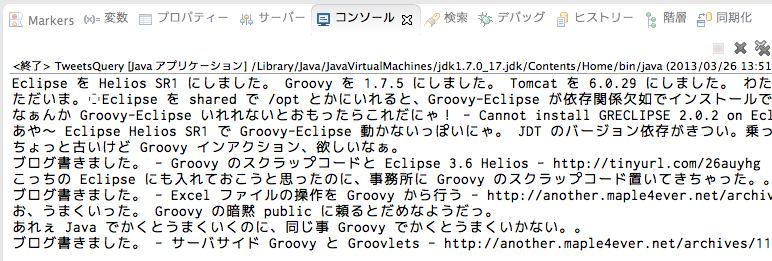
なんだか懐かしいツイートがいっぱいでてきました。。
ちなみに5万弱のレコード数でしたが、それぞれの処理は待つ暇なく終わっています。
ワンショットとはいえ、普通のサーバ型の RDBMS を使ってしまうとプロジェクトだけでアプリを管理できずポータブル性がなくなってしまいますので組み込みDBの形式は便利ですね。サーバの起動にやきもきすることもありません。
また、OrientDB はドキュメント型ということで、スキーマレスで扱えるのもこういった用途に気軽で良いです。 このソースでは手抜きしていますが、POJO へのマッピングもできますのできちんとかくこともできます。
なんだかものすごいプロダクトをこんなことに使っていいんだろうか、、とも思ってしまいますが、、使い方のひとつということでお許しを。。 🙂