去年くらいからつくりはじめていた、libymfm.wasm ですが、GitHub のリポジトリーにコミットするだけで、ブログにあまりあれこれ書いていませんでした…!(ので書いてみます)
libymfm.wasm は WebAssembly 上で動作する(主に) FM 音源シンセサイザーをエミュレートして PCM を生成するライブラリーです。ゲームなどのプログラムへの組み込みを考えて作成されました。
https://github.com/h1romas4/libymfm.wasm
This repository is an experimental WebAssembly build of the [ymfm](https://github.com/aaronsgiles/ymfm) Yamaha FM sound cores library.
FM 音源エミュレータコアとしては、多目的エミュレーションフレームワーク MAME の新 YAMAHA FM 音源エミュレーションコアを由来とする C++ でかかれた ymfm を使わせて頂いています。
ymfm の作者は MAME の中の人のアーロンさんで、元々 MAME 内での実装だった新 YAMAHA FM 音源コアを 3rdparty ライブラリー化したのが ymfm となります。

従来の MAME の FM 音源エミュレーションコアは YM2151 や YM2203、YM2612 などなど別チップは別エミュレーションの実装となっていましたが、機能差分以外は同じ回路が使われているのではないかという仮説から、 decap 解析などとの比較を経て完成したライブラリーです。ということで、ymfm は多くの YM 系のチップをそのひとつでサポートしています。
さて、表題の libymfm.wasm ですが、ymfm を使いながら、Rust でかかれた次のような実装を加えています。
VGM/XGM 形式のシーケンサーを搭載
VGM/XGM 形式の演奏形式をサポートしています。ファイルを渡すだけで発音可能です。
VGM はサポートしているサウンドチップのみ、またデーターブロックの圧縮が未サポートなどフル実装ではありません。XGM は PCM に不具合ありで修正予定です。 (多くのデータでテストはされていませんが修正済み)
サンプリングレートコンバート
各サウンドチップが出力するネイティブサンプリングレートはまちまちなので(YM2151 が 3.58MHz 動作で 55.9kHz 等々特殊です)、扱いやすいように指定したサンプリングレートにアップ、ダウンサンプリングで統一して PCM 出力します。
クロックの制御
ライブラリーに、出力サンプリングレートに対して何サンプル分の PCM が欲しいのか(時間をどれくらい進めるのか)を指定できます。これはゲーム組み込み用などで、1フレーム分のサンプルが欲しいケースや、バッファリング再生したい時に便利です。
WebAssembly 向けのインターフェース関数
ハイレベルインターフェースとして vgmplay xgmplay 関数、ローレベルインターフェースとして各サウンドチップに直接レジスターライトして、結果を任意のサンプリングレートとフレーム数で PCM 取得できます。
追加のサウンドチップ
ymfm サポート以外のサウンドチップも MAME からの移植でいくつか実装。主にメガドライブ、セガアーケード、X68K 構成を想定したチョイスです。
ライセンス
ymfm や追加音源、libymfm.wasm 全て BSD ライセンスになっています。
WebAssembly ライブラリー形式となっていますので、同一 .wasm シングルバイナリー(3MB 程度です)で Wasmer などの各言語向け WebAssembly バインディングを使うことで、ほとんどの OS、コンピュータ言語からコールして容易に使うことができます。 .wasm ファイルひとつで全環境動くので扱いやすいです。もちろんウェブブラウザーでも…!
リポジトリには Python からコールする例を入れています。リンク先の手順ですぐ発音すると思いますので、良ければ遊んでみてください〜。
VGM/XGM 再生
関数に VGM/XGM ファイルを与えると指定したチャンクサイズで PCM を取得できます。
sample_vgmplay.py 抜粋
# Output sampling rate settings
SAMPLING_RATE = 44100
SAMPLING_CHUNK_SIZE = 4096
# ...snip...
# Create Wasm instance
chip_stream = ChipStream()
# Setup VGM
header, gd3 = chip_stream.create_vgm_instance(VGM_INDEX, "./vgm/ym2612.vgm", SAMPLING_RATE, SAMPLING_CHUNK_SIZE)
# Print VGM meta
print(header)
print(gd3)
# Play
while chip_stream.vgm_play(VGM_INDEX) == 0:
# Get sampling referance
s16le = chip_stream.vgm_get_sampling_ref(VGM_INDEX)
# Sounds
sample = pygame.mixer.Sound(buffer=s16le)
pygame.mixer.Sound.play(sample)
# Wait pygame mixer
while pygame.mixer.get_busy() == True:
pass
サウンドチップダイレクトコール
以下の例は あぶり6800 さんの Z80 MSX サウンドドライバー(1/60 tick) の Python によるシミュレートで、YM2149 の SSG を発音させています。
ソースコードでは YM2149 ひとつを扱っていますが、サウンドスロットにぽこぽこ複数の音源を追加してレジスターライトして PCM を取得できるイメージです。
前述の vgmplay(xgmplay) で使っているインターフェースは全て Wasm 側にも公開しているので、PCM ROM がある音源の操作も含め、原理的には自前で vgmplay をかけるスペックになっています。
sample_direct.py 抜粋
# Create Wasm instance
chip_stream = ChipStream()
# Setup sound slot
chip_stream.sound_slot_create(SOUND_SLOT_INDEX, SOUND_DRIVER_TICK_RATE, SAMPLING_RATE, SAMPLING_CHUNK_SIZE)
# Add "one" YM2149 sound chip in sound slot
chip_stream.sound_slot_add_sound_device(SOUND_SLOT_INDEX, SoundChipType.YM2149, 1, YM2149_CLOCK)
# YM2149 initialize (write reg: 0x7, data: 0b10111000)
mixing = 0b10111000
chip_stream.sound_slot_write(SOUND_SLOT_INDEX, SoundChipType.YM2149, 0, 0x7, mixing)
# ...snip...
# Write YM2149
chip_stream.sound_slot_write(SOUND_SLOT_INDEX, SoundChipType.YM2149, 0, track + 0x8, volume)
さて、libymfm.wasm のプログラム部分についてですが、Rust でかいており、C/C++ の ymfm を wasi-sdk でビルドした上で、Rust の wasm32-wasi とリンクする形でビルドしています。
このことから、.wasm は WASI の形になっています。(とはいえ、現在のところは WASI の機能はほとんど使っていません。一部、YM2608 の ROM ファイル読み込みで機能しています)
ウェブブラウザーインターフェースでは、WASI をブラウザー上で動作させるため、wasmer-js を使い、WASI バインディング関数をシミュレートして動作させています。
ウェブブラウザーインターフェースは次のリンクから試すことができ、演奏ファイルのドラッグアンドドロップ(複数可能)で楽曲が再生されるはずです。(画面クリックでもデモ曲が演奏されます)

libymfm.wasm とは直接関係ありませんが、ウェブブラウザーの JavaScript の実装的には AudioWorklet と Woker と SharedArrayBuffer を使った音声出力の実装になっています。
iOS/macOS の Safari は現時点で SharedArrayBuffer に対応しているものの、どうも SharedArrayBuffer の notify がうまく飛ばないようで発音しません。どうやら AudioWorklet に渡された際に共有ではなくコピーになるようです。Safari 16 で修正されそうです(SharedArrayBuffer posted to AudioWorkletProcessor is not actually shared with the main thread)
(2022/8 追記。Safari Technology Preview 149 で修正されているのを確認しました)
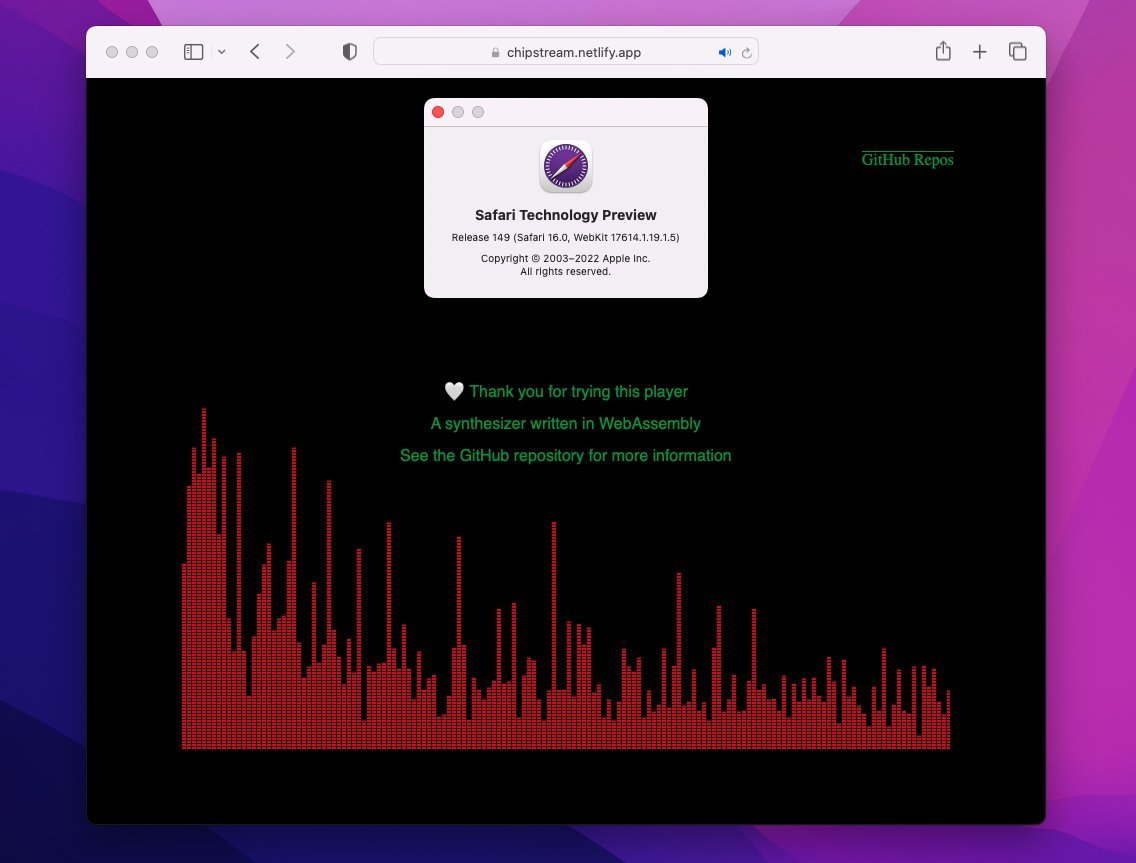
Windows/macOS/Linux の各ブラウザーで音切れしないように確認しながらつくっていますが、まだだめな環境があるかもです。。結構苦戦しました。。ちなみに手元の環境では、Linux の Firefox が一番素直に動作するようです。
てなわけで、みなさまのアプリに組み込みが容易になっている libymfm.wasm の紹介でした。新作ゲームに FM 音源ミュージックのリアルタイム再生など、いかがでしょうか…!
JavaScript、Python のサンプル実装含めてソースコードは、GitHub にコミットしてありますので、良ければ見てみてください。
https://github.com/h1romas4/libymfm.wasm
This repository is an experimental WebAssembly build of the [ymfm](https://github.com/aaronsgiles/ymfm) Yamaha FM sound cores library.
時折あるアップデート通知は https://twitter.com/h1romas4 のツイッターにて〜 😀