
技術書系のドキュメントを書く場合に使いたくなる表現をテキストで書きたいなと考え、以前からつくっていた「Asciidoctor と Gradle でつくる文書執筆環境」というドキュメントを刷新してみました。 AsciidoctorとGradleでつくる文書執筆環境(HTML version) AsciidoctorとGradleでつくる文書執筆環境(PDF version) 同人系の PDF 本技術書執筆環境としても使えそうなので、試行的に BOOTH 頒布もしてみています。...
技術書系のドキュメントを書く場合に使いたくなる表現をテキストで書きたいなと考え、以前からつくっていた「Asciidoctor と Gradle でつくる文書執筆環境」というドキュメントを刷新してみました。 AsciidoctorとGradleでつくる文書執筆環境(HTML version) AsciidoctorとGradleでつくる文書執筆環境(PDF version) 同人系の PDF 本技術書執筆環境としても使えそうなので、試行的に BOOTH 頒布もしてみています。...

技術文書などでファイルとディレクトリ・フォルダ構造を図解したい場合に、テキストを使った定義から .svg や .png を生成する方法メモです。 出力例: いくつか方法があると思いますが、Docker - PlaantUML Server と VS Code - PlantUML 拡張を使うとお手軽にいけると思います。...
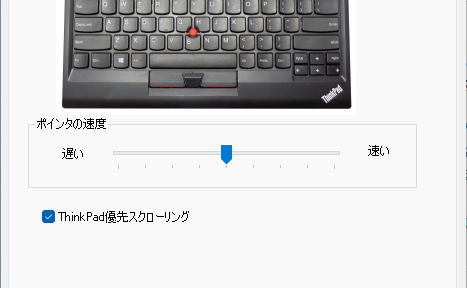
USB (有線)版の ThinkPad トラックポイント・キーボードで、真ん中ボタンによる縦スクロールを行った場合に「ThinkPad 優先スクローリング」機能がダウンする場合があります。抜本的に解決できませんでしたがメモ。...
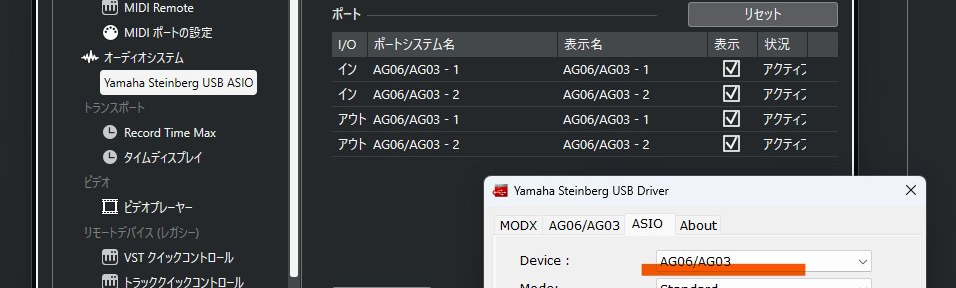
新規の Windows 11 に Cubase を導入していて分からなくなったので備忘録にて。 Windows に ASIO 機器を複数台接続した場合に、Cubase 上に選択したい機器のポートが表示されませんでした。...

Xbox Series S|X のリリースノートで「Xbox コントローラーのファームウェア アップデート」とある場合に、手動でコントローラのファームウェアをアップデートする方法がぱっと分からなかったのでメモしておきます。 Xbox コントローラーのファームウェア アップデートコントローラーを最新のソフトウェアにアップデートしておくと、コントローラーの機能と互換性を最大限に活かすことができます。...
Xbox Series S|X 良いです…!(3回目) 2022/10 現在 Xbox Series S が在庫もあり購入しやすくなっています。もしかすると初 Xbox という方もいらっしゃるかもしれません。...

Xbox Series S|X 良いです…!Xbox 史上最高傑作のマシンではないかと思います。(XBOX を初代から買い続けたユーザより) てなわけで 2022/10 現在のTIPS 的な設定を書きいておきます。...

1980年代から90年にかけて家庭に広く普及した MSX パソコン(当時はマイコンと言ってましたね!)にて、ゲームをつくる活動を 2022年に復活してみました…! 当時の開発は MSX-BASIC もしくは Z80 アセンブラをつかったものでしたが、今回は さまざまな 8bit Z80 系のレトロコンピュータに対応する Z88DK ツールチェインによる C 言語を使っています。 Home: z88dk z88dk is the only C and assembler development kit that comes ready out-of-the-box to create programs for over 100 z80-family machines. Z88DK のセットアップやサンプルコードについては、以下の文書にまとめています。...
この記事はゆるWeb勉強会@札幌 Advent Calendar 2021の 3日目の記事です。 去年のアドベントカレンダーより… 自分は、去年のゆるWebアドベントカレンダーで書きました… WebAssembly をウェブブラウザーで活用する(1)次の回では、C/C++ もしくは Rust でかかれたプログラムを WebAssembly に移植して動作させるデモをやってみたいと思います!(続く 次の回になるまで 1年かかりました…(すいませんw というわけで、今年の記事はここ数ヶ月取り組んでいました C/C++/Rust のプログラムを WebAssembly で動作させた顛末を例に、Wasm(WebAssembly の略です) の周辺技術事情やキーワードを書いていきたいと思います。...

はじめに しばらく品切れが続いていました M5Stack Core2 を買うことができました。嬉しいです。...
はじめに ビシバシチャンプ…。 ふと思いつきまして Netlify で使える Lambda なサービス、Netlify Functions を用いて参照系検索 API を作成してみました。...
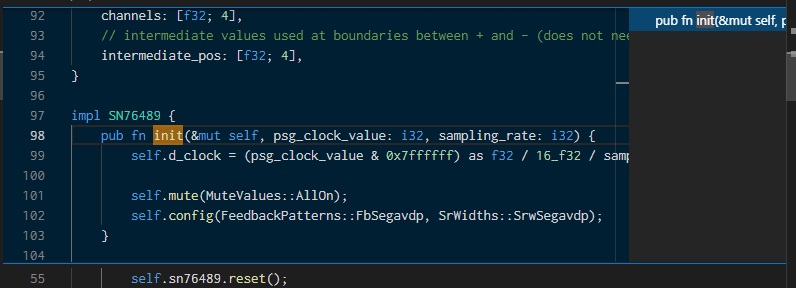
Visual Studio Code Advent Calendar 2018 の 16日目です。...
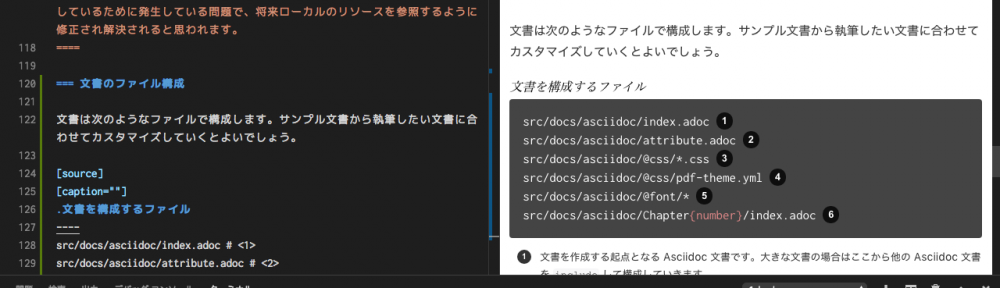
技術文書を書く環境が欲しくなり、VS Code と Gradle を使って Asciidoc 文書を執筆する環境を整えてみました。 お手軽に構成できて、300ページくらいの文書でも耐えられそうです。...

初代プレイステーションと連携して動く 1999年発売の携帯ゲーム機 PocketStation(ポケステ) をお友達が発掘してお借りすることができたので、当時流行っていた、ポケステをゲーム機として使わずに ARM マイコンとして遊ぶプレイを蘇らせてみました。 :P さすがにこれだけ年数が経過すると解説しているサイトさんも消え始めていていますので、2018 年版ポケステ・Hello World の手順を書いてみたいと思います。...
Visual Studio Code Advent Calendar 2017 の 13日目の記事です。 :) 昨日の「Visual Studio Code の PHP 言語サポート vscode-php-intellisense 2017年版」に続きまして今日は VS Code と Arduino による電子工作です。...

本記事の 2017 年版を記載しましたのでご参照ください。 https://another.maple4ever.net/archives/2321/ Visual Studio Code Advent Calendar 2016 の 12日目です! ここのところずっとウォッチしていました、Visual Studio Code(vscode)で利用可能な PHP サポート拡張になります "vscode-php-intellisense" が完成度をあげ、かなり良い感じになっています。...
6/13(土) OSC 北海道 2015 2日目に、WordBench 札幌と baserCMS ユーザ会の名前で、セミナーとブース出展を行ってまいりました。 :) 今年のセミナーは WordPress を WP Multibyte Patch プラグインでおなじみ tenpuraさん(倉石さん)にお願いし、ぼくのほうは baserCMS のセミナーを担当させていただくという布陣で参加しています。...

去年くらいから体調があまり良くなく(歳ですゆえ…)、運動不足解消のためにと最近クロスバイクを買ってサイクリングを始めました(^ ^ 実は買うまでクロスバイクの由来も知らなかったのですが、山を走るマウンテンバイクと、スピードレースをするロードバイクの間の子とのこと。 購入車種は Marin Bikes の MUIRWOODS SE 19 インチ。...

2014/6/21(土) に開催されたオープンソースカンファレンス北海道にて、WordPress と baserCMS のセミナー & ブース出展を行ってきました! 今年はSaCSS(sapporo.css)ブースも加わり、メンバーのみなさまのご協力のもと、無事終了することが出来ました。ありがとうございました。...

第2回 baserCMS デザインテーマコンテストで「店舗系テーマ賞」を頂きました!第1回に続き、2回目の受賞となり嬉しく思っています :D 受賞者発表!! | 第2回 baserCMS デザインテーマコンテスト 制作:こもりこめろましゃ baserCart (basercart-1.0.0) デザイン性と機能性が両立できる baserCMS を活かすべく制作したショッピングカートサイトテーマです。 森のお店をイメージしたかわいいデザインにしてみました。...

Kindle Fire の 3000円割引最終日に、Grails2 系の洋書がいくつかでていることに気がついてしまったのが運の尽き・・・。 スマートフォンや 10インチ Android タブレットの Kindle アプリで読んでみたものの、小さすぎ大きすぎ。...

札幌のウェブデザイナー・コーダーのためのセミナー・勉強会 SaCSS(sapporo.css)にて、5/24 に催されました「WordPress10周年記念! SaCSS WordPress特集2013」に行ってまいりました。 WordPress10周年記念! SaCSS WordPress特集2013 @hiromasa :「WordPress10周年記念でひろましゃが語る!WordPress の新機能と最新動向」 @se_ino :「WordPress を初めて使って」 @komomoaichi :「WordPressで覚えるPHP入門」 @h2ham :「Webデザイナーの仕事におけるWordPressとテンプレート」 WordPress 日本語化チーム、Multibyte Patch Plugin でおなじみの倉石さんも来られまして、札幌からも 10周年おめでとうのメッセージを送ることができて良かったです! パチリ。...
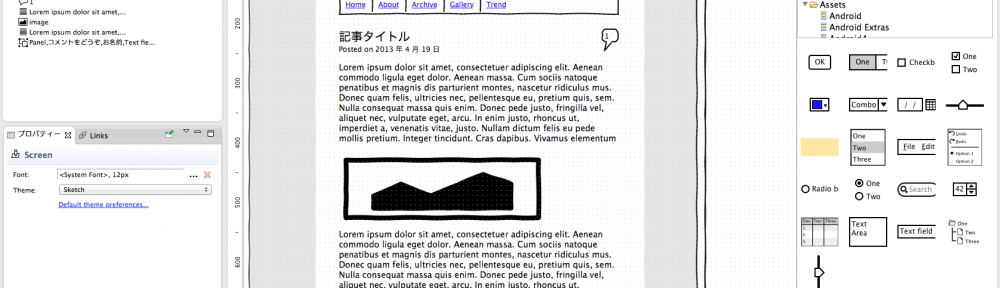
以前、サイトを眺めてすごいなぁと思っていたものの、有料($99)だったため試さなかった、WireframeSketcher を本日購入してみました。 用意された部品や操作系を元に、アプリケーション開発時のワイヤーフレームやモックアップなどのドキュメント作成を支援するソフトウェアです。...
実家の ThinkPad X200s が壊れたということで、ThinkPad T530 が新たに登場です。 :) 音声のノンリニア編集をしなければいけないということもあり、奮発して 8G メモリの Windows 7 64bit 版。...
会社に行くのに使っていたカバンが、ぼろぼろになってしまったので新しいカバンを買いました。 せっかくなのでパソコンを入るものをということで、、いつもの Lenovo さんのサイトを見ていたら、それはもういいだろう・・・と最近よく登場しますわたくしの上司、ももいろ上司Zがいろいろ見て選んでくれました。...
なんといまさら感がある記事名ですが、ここで Windows 7 をデスクトップPCに導入しました。 発端はこの PC(Shuttle SN78SH7)が最近の Linux のカーネルと大変相性がよくないこと。...